
git good
Cursor just bought the best abstraction layer over version control, and I'm here for it

Last week, Cursor announced it was acquiring Graphite. I think this acquisition will prove to be one of the more consequential moves in the AI development tooling space, and I want to explain why.
I’ve been a Graphite user since before the AI buzz. Back when it was purely a stacked PRs tool. What made it useful was how it forced me to think of work as a sequence of ordered, dependent milestones. That framing matters even more now as AI agents need a concrete way to understand progress, causality, and what comes next. Stacked PRs provide precisely that.
A quick primer
Graphite has leaned heavily into its AI code-review tooling, but at its core, it remains the best stacked pull request service available to the public.
Large tech companies have long had internal tools built around stacked pull requests, such as Meta’s Phabricator. The stacked diffs pattern treats code changes as an ordered sequence of small, dependent diffs rather than monolithic feature branches.
Graphite emerged from alumni of those companies that missed using that workflow. You can technically do stacked PRs with pure git. Create a branch, make a commit, create another branch off that one, make another commit, and so on. The problem comes when you need to make a change to a PR near the bottom of the stack. You have to rebase every branch above it, resolve conflicts at each step, and force push all of them. It becomes unwieldy fast.

Graphite handles this automatically. You make your change, run gt modify, and the tool restacks everything above it. The complexity is still there under the hood, but you do not have to manage it manually.
This is similar to how Python relates to assembly. Assembly is still there. The CPU still executes low-level instructions. But you write in a higher-level language that maps to how you think about the problem. Graphite gives you stacks, milestones, and dependencies as your working vocabulary. Under the hood, it is still git, still branches, still commits. But the interface matches how you actually think about the work.
More recently, Graphite has been building toward AI-assisted code review. They have an AI reviewer that catches bugs and enforces consistency. The direction is toward a future where the boundaries between writing and reviewing code collapse into a single iterative process.
Cursor started as a VS Code fork with tighter AI integration back when GitHub Copilot was still maturing. Since then, it has found its own footing as an agentic IDE, one where AI is not just autocompleting lines but actively working through multi-step tasks. The acquisition brings together the environment where code is written and the platform where it is reviewed.
Stacked PRs encode structure
The standard argument for stacked PRs is reviewability. Smaller PRs are easier to review, and that is true. But the deeper value is that stacking encodes ordering, dependency, and intent. When you decompose a feature into a stack, you are making explicit decisions about what comes first, what depends on what, and where the logical boundaries are.
A monolithic PR is a side effect of development. A stack is a representation of a plan.
This connects directly to AI agents. A stack is a concrete artifact that maps from “build a reporting dashboard” to “first build the query layer, then aggregations, then export functionality, then visualization components, then the UI.” That sequencing reflects architectural decisions about dependencies and risk. An agent operating within a stack knows what came before and what comes next. It has landmarks.
The dimensionality problem
I find it helpful to think about development work in terms of dimensions. Most teams operate at zero or one dimension. The jump to two dimensions has historically been too costly to attempt.
Zero dimensions: The monolith

One massive PR per feature. No internal structure. Progress is binary: done or not done. This is the default GitHub workflow. You branch off main, build until complete, open a PR, and wait for review.
The monolith is easy to create but painful to review. Merge conflicts accumulate the longer the branch lives. If something goes wrong after the merge, rollback means losing everything. For minor changes, this works fine. For anything substantial, it becomes a compounding bottleneck.
One dimension: The stack

core.py are for the CSV export, not the query builder.A feature is decomposed into sequential milestones. Each PR is atomic and reviewable on its own terms. The stack encodes the order. This is what Graphite enables, building on patterns from Phabricator.
Each milestone is a checkpoint. If milestone three has a problem, you can address it without unwinding milestones one and two. The work has a structure that survives contact with reality. One-dimensional stacking is manageable with discipline and tooling. The limitation is that you are still working on one feature at a time.
Two dimensions: The matrix
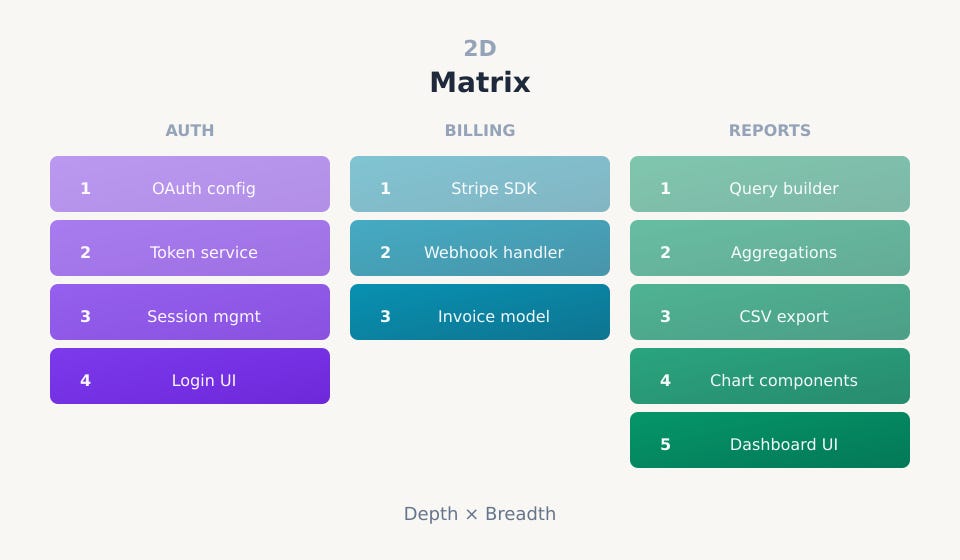
Multiple features in flight simultaneously, each with its own milestone stacks. Auth, billing, and reporting are all progressing in parallel, each with its own independent decomposition that reflects its architectural needs.
Managing a matrix with traditional tooling is nearly impossible. You are juggling multiple stacks, each with its own rebase chains, each potentially touching shared code. The coordination overhead grows faster than the benefits of parallelism. In practice, teams serialize work to avoid complexity.
Putting it together
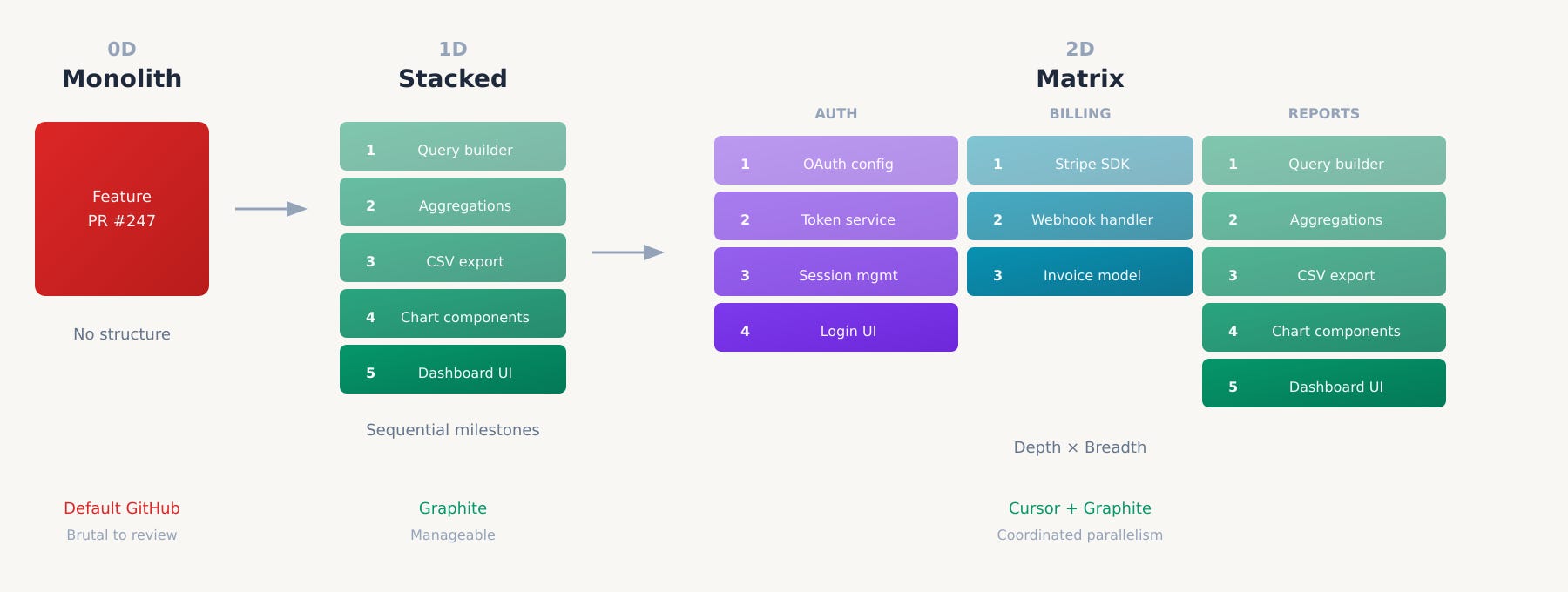
The progression from zero to one to two dimensions is about the richness of representation. A monolith tells you nothing about structure. A stack encodes sequential dependencies within a feature. A matrix encodes the full topology of work in progress.
That richer representation is what AI agents need to operate effectively. An agent working on a monolithic PR has no landmarks. An agent within a stack knows what came before and what comes next. An agent aware of the whole matrix understands its own trajectory and how it relates to concurrent work happening elsewhere in the codebase.
Why Cursor plus Graphite changes the calculus
The parallel agent workflow is already emerging. Developers use git worktrees to spin up multiple Cursor or Claude Code instances on separate branches. Cursor now supports multiple concurrent agents. The pattern works, but coordination is manual, and merging can be chaotic.
Cursor plus Graphite enables coordinated parallelism. If the tools share context, if Cursor knows about the stacks and Graphite knows about the architectural decisions made during development, then agents can be aware of each other’s intent without collapsing into merge conflicts.
The stacked PRs provide vertical structure: this milestone depends on that one. The shared context from Cursor provides horizontal coherence: these features are independent but part of the same plan. And because Graphite operates as an abstraction layer over git, you can reason about milestones and progress rather than branches and rebases. The underlying git primitives are still there, just like assembly is still executing when you run Python.
When Cursor and Graphite share context, a stacked PR carries forward the intent, the architectural reasoning, and the decisions from the development session that produced it. The reviewer does not have to reconstruct why this change exists. The PR becomes a checkpoint in a legible plan.
What I am watching for
The Cursor announcement mentions “tighter integrations between local development and pull requests, smarter code review that learns from both systems, and some more radical ideas we can’t share just yet.”
I will be watching whether the integration enables true matrix development: parallel feature stacks that are independently ordered but collectively coordinated. If it does, that is a genuine workflow shift. If it ends up being a faster review on the same one-dimensional workflow, it is an incremental improvement on an already good product.
Either way, the acquisition signals that the industry is taking the outer loop seriously. Code generation is approaching being a solved problem. The interesting questions now are about coordination, review, and how humans and agents share a representation of what is being built and why.
yeah no, I don’t post here often enough to justify asking you to subscribe. honestly just ping me if you ever want to hear me go on a soapbox.
Strong take on the dimensionality framework. The stack-as-plan framing is exactly right, especially when thinking about agent coordination. I've been testing parallel worktrees with Cursor and the manual merge choreography gets ugly fast. What's underappreciated is how stacked PRs dont just help reviewers, they encode architectural intent that agents can actualy use as context. The two-dimensonal matrix feels like the unlock here if Graphite's rebase automation holds up under multi-agent load.